Which LLMs Can Actually Code Genetic Algorithms That Work?
I tested 11 SOTA models on Snake AI. Grok's 96 lines vs. GPT-5's 368.

I won’t bury the lede. Here’s the cool part:
I was recently building a Minesweeper Deep learning system, and was stuck, I turned to GPT-5 and it confidently built me a solver that it ASSURED me would hit 40% on expert boards. Zero percent actual solve rate, hundreds of lines of sophisticated-looking nonsense.
I wanted to know which models can truly design algorithmic systems that work, not just generate confident-sounding code. So I used the classic Snake game as a test.
The Challenge
Design a complete genetic algorithm to train a neural network to play Snake. Same rules for everyone.
The setup:
Fixed network architecture (17 inputs → hidden layers → 3 outputs)
500 generations of evolution
Standardized evaluation harness
Pure code generation, no human edits
The Harness
I built a fair testing ground where every model faced identical constraints:
class MLP:
def __init__(self, in_dim, h1, h2):
self.in_dim, self.h1, self.h2, self.out_dim = in_dim, h1, h2, 3
self.num_weights = (in_dim * h1 + h1) + (h1 * h2 + h2) + (h2 * self.out_dim + self.out_dim)
Fixed components:
10x10 Snake board
17-dimensional observation space (wall distances, food vectors, danger signals)
3-action space (turn left, go straight, turn right)
2-hidden-layer MLP architecture
What they could tune:
Population size
Mutation rates
Crossover strategies
Reward functions.
What they could not:
The network
Action space
Observations
The Prompt
Each model got identical instructions via OpenRouter with 10k reasoning tokens:
Goal: You are an expert in machine learning. Your task is to design the core algorithms for an AI that learns to play Snake. I am providing a test harness that defines a fixed neural network architecture (MLP class) and handles all simulation.
Your goal is to provide the best possible configuration, reward function, and genetic algorithm to train this fixed network.
CRITICAL SYSTEM DETAILS - READ CAREFULLY:
1. The Network Architecture is FIXED:
The harness provides a 2-hidden-layer MLP. You cannot change this structure.
Your primary architectural decision is choosing the number of neurons for HIDDEN_LAYER_1 and HIDDEN_LAYER_2 in your config.
2. The Action Space is FIXED (3 Actions):
The network has 3 outputs: [Turn Left, Go Straight, Turn Right].
3. The Observation Space is FIXED (17 Inputs):
The network receives 17 inputs.
Your file MUST contain these THREE components:
A function get_config() that returns a dictionary of hyperparameters. You MUST use the key names shown in the example below (POP_SIZE, HIDDEN_LAYER_1, etc.).
A function calculate_reward(env, ate_food, is_alive).
A create_ga_instance(num_weights, pop_size) function and a GeneticAlgorithm class with ask() and tell() methods.
Do NOT include an MLP class or any code for the environment or main loop.
Here is the required structure and an example get_config. Please fill it in:
Python
# solution.py
import numpy as np
1. HYPERPARAMETERS
def get_config():
"""
Return a dictionary of hyperparameters for the fixed 2-layer MLP.
MUST use these exact key names.
"""
return {
"POP_SIZE": 512,
"GENERATIONS": 300,
"HIDDEN_LAYER_1": 24, # You tune this value
"HIDDEN_LAYER_2": 16, # You tune this value
# --- Add your GA-specific hyperparameters below ---
"MUTATION_RATE": 0.1,
"TOURNAMENT_SIZE": 5,
# ... etc ...
}
2. REWARD FUNCTION
def calculate_reward(env, ate_food, is_alive):
# ... your implementation ...
3. GENETIC ALGORITHM
def create_ga_instance(num_weights, pop_size):
return GeneticAlgorithm(num_weights, pop_size)
class GeneticAlgorithm:
# ... your implementation ...
Then I let each model work, ran their code through 500 generations (about 4 hours total), and collected the data.
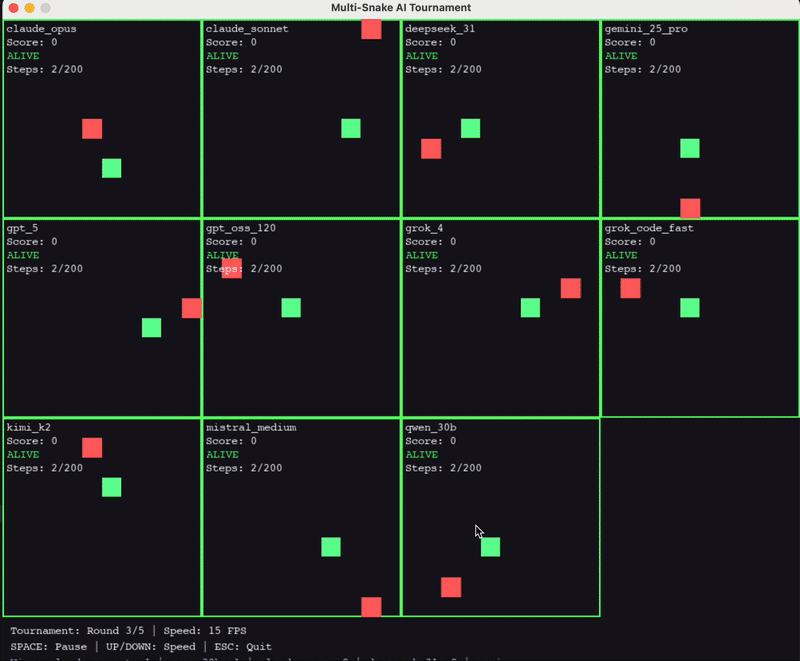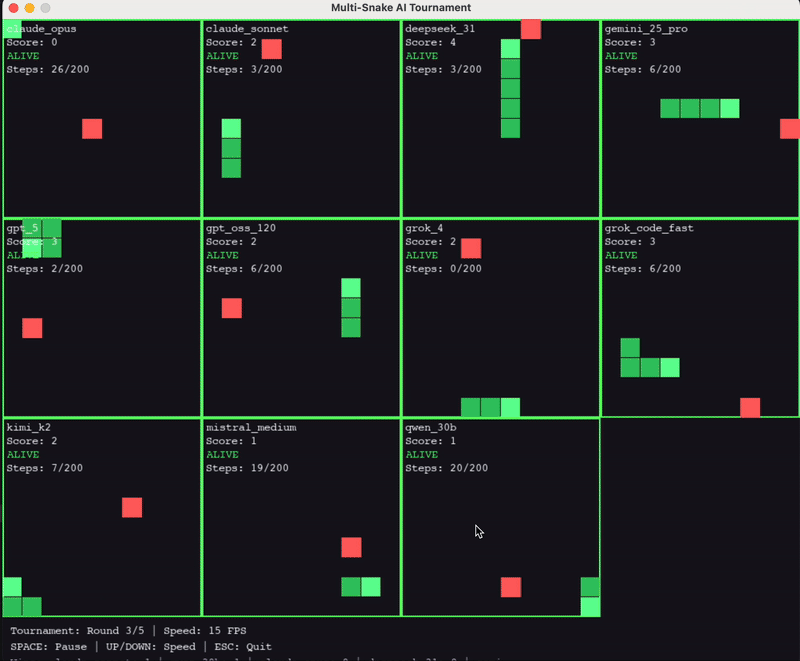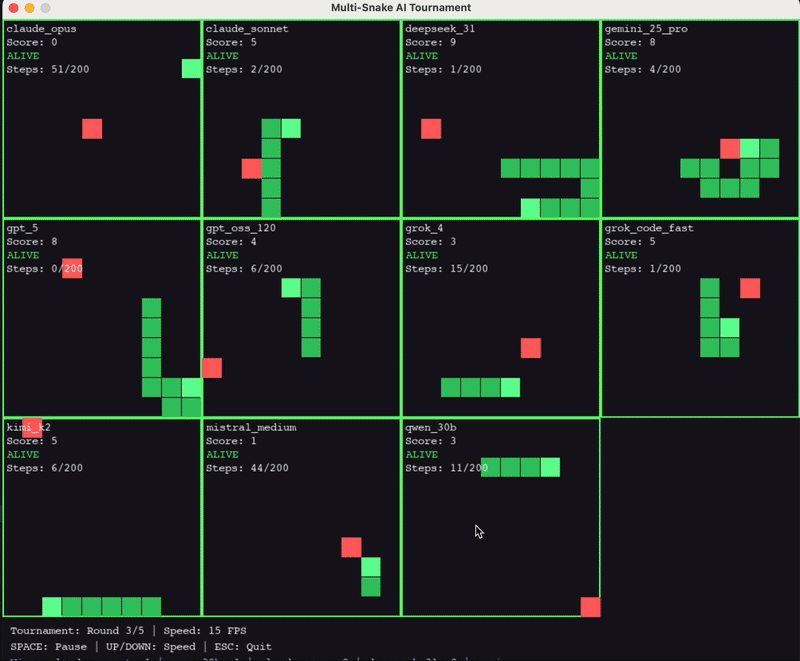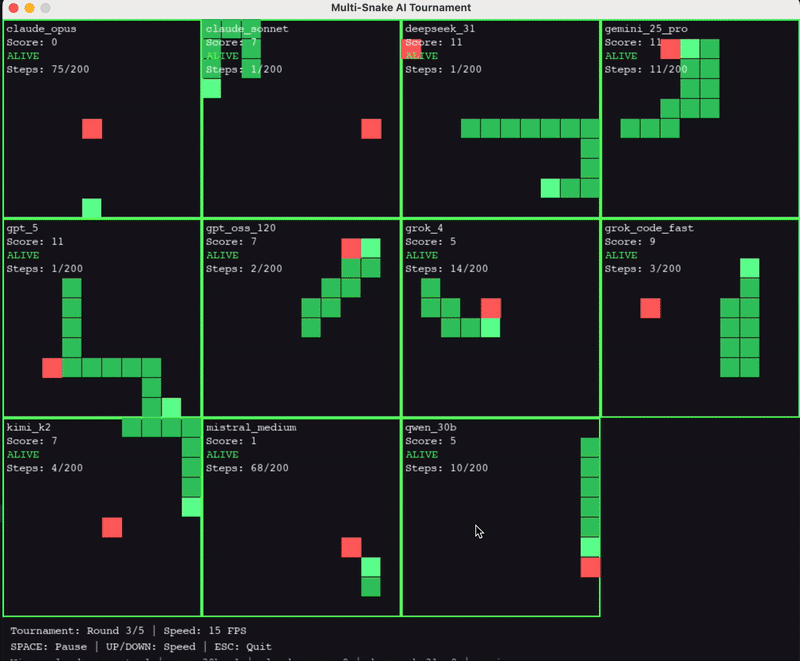
The Results
After 500 generations, here's where they landed:
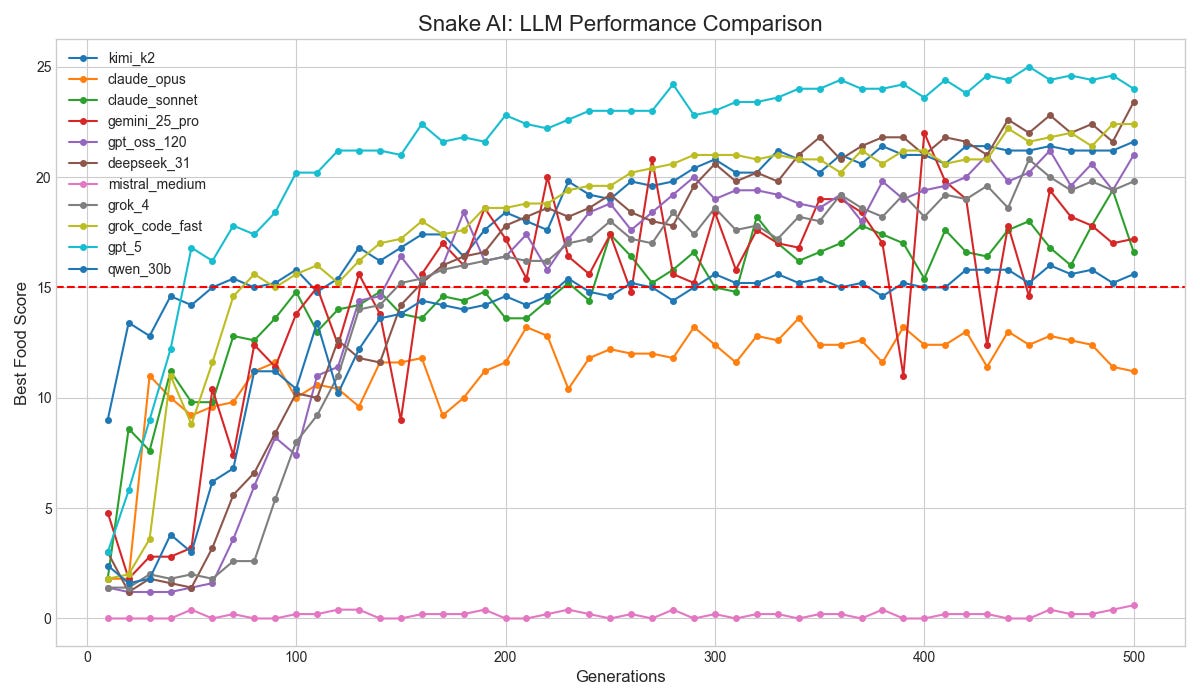
GPT-5 takes the throne, but there are some interesting caveats to this.
Code Philosophy: Complexity vs. Performance
Three different approaches emerged at the top.
The Minimalist: Grok Code Fast (96 lines)
def calculate_reward(env, ate_food, is_alive):
reward = 0
if ate_food:
reward += 100 # High reward for eating food (primary goal)
if not is_alive:
reward -= 100 # Heavy penalty for dying
reward -= 1 # Per step penalty to discourage loops
return reward
No fluff, purely essentials. It learns fast (generation 80) and reaches 22.4 peak performance, where ‘peak’ means the highest average food score per episode achieved at any generation.
The Engineer: GPT-5 (368 lines)
def calculate_reward(env, ate_food, is_alive):
# Robust environment attribute detection
def _try_snake_head(e):
if hasattr(e, "snake") and isinstance(e.snake, (list, tuple)):
head = e.snake[0]
if isinstance(head, (list, tuple)) and len(head) >= 2:
return (float(head[0]), float(head[1]))
# ... 20 more lines of fallback detection
# Distance-based progress rewards
dx = food[0] - head[0]
dy = food[1] - head[1]
curr_dist = float(np.sqrt(dx * dx + dy * dy))
# Normalized progress with board diagonal scaling
progress_reward = progress_scale * (prev_dist - curr_dist) / max_dist
# Anti-stagnation penalties
reward += -1e-4 * steps_no_food
# ... plus sophisticated episode tracking
GPT-5 built a ridiculously convoluted snake game: robust environment detection, distance-based progress shaping, anti-stagnation penalties, adaptive mutation decay, blend crossover options, weight clipping. All that nuance did work; however, reaching 25.0 peak by generation 50.
Efficiency Analysis
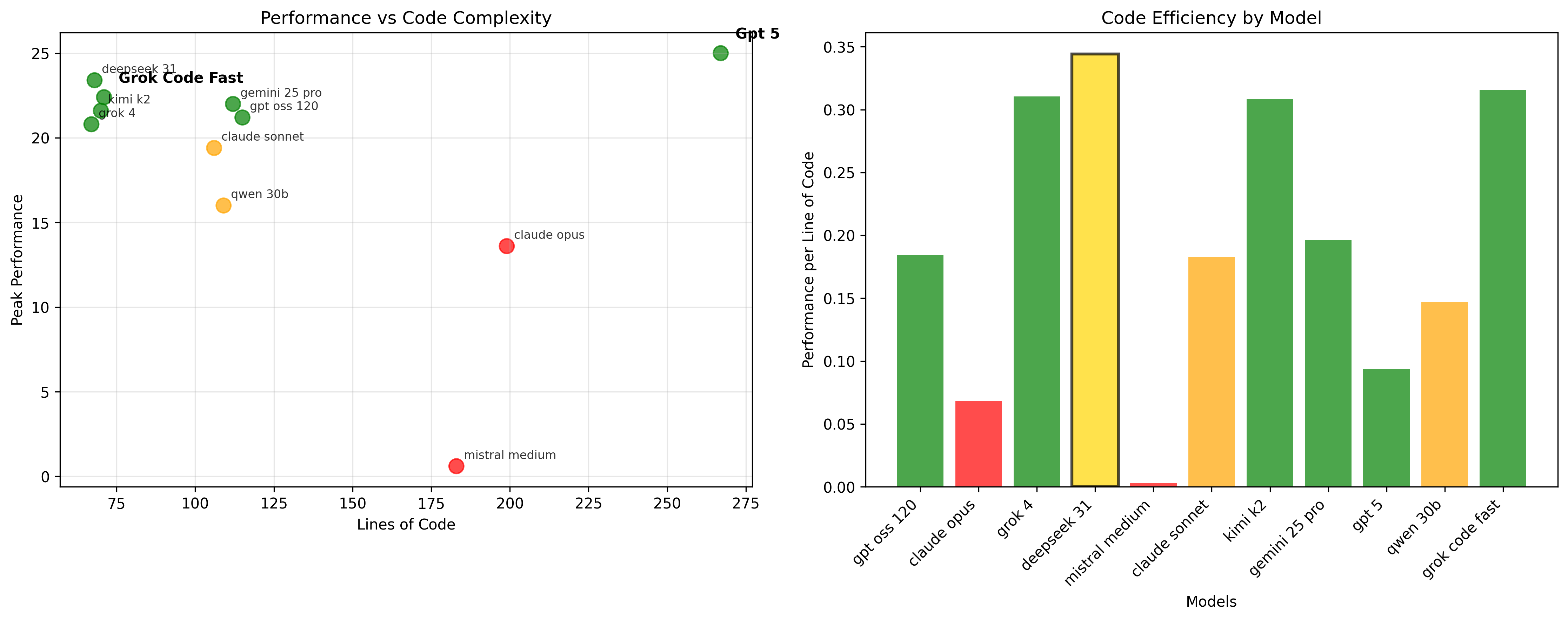
The data reveals three distinct architectural philosophies:
Efficiency Masters
Grok Code Fast: 96 lines → 22.4 peak (0.23 performance/line)
Deepseek 3.1: 86 Lines → 23.4 peak (.27 performance/line)
Balanced Engineers
Gemini-2.5-Pro: 178 lines → 22.0 peak
Claude Sonnet 4: 156 lines → 19.4 peak
GPT-OSS-120b: 178 lines → 21.2 peak
Find it really interesting they converged on such similar solutions despite being in 3 separate model families.
The Over-Engineers
GPT-5: 368 lines → 25.0 peak (0.07 performance/line)
Claude Opus: 284 lines → 13.6 peak
Mistral Medium: 254 lines → 0.6 peak
What Went Wrong
Mistral Medium: Generated sophisticated-looking code riddled with bugs. Never learned anything across 500 generations.
Claude Opus: Chose overly conservative hyperparameters and never broke through the learning threshold in 500 generations. Safe code that accomplishes nothing (very Anthropic fitting)
Try It Yourself
The entire benchmark is open source:
git clone https://github.com/Ryandonofrio3/snake-ai
cd llm-snake-benchmark
uv run eval_harness.py --solution gpt_5
uv run analyze.py
uv run multiview.py
For my next RL project, I'd likely choose DeepSeek-3.1 or Grok Code Fast. They deliver strong performance with code you can actually understand and maintain for future tweaks!
This benchmark cost about $2 and 12 hours of compute time. The insights into model capabilities were worth every minute of watching those learning curves climb!